Large Language Models (LLMs), like GPT-4 and Bard, have revolutionized AI, offering
human-like text generation for various applications. However, they are prone to "hallucinations,"
where outputs appear coherent but are factually inaccurate or illogical. This issue poses risks,
especially in fields like healthcare, law, and education.
Causes of Hallucinations:
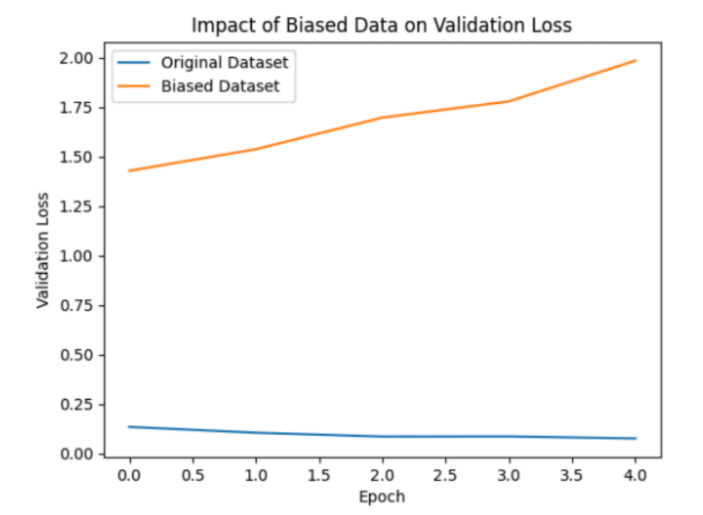
Training Data Gaps:Incomplete, outdated, or biased datasets lead to fabricated or
incorrect responses.
The figure below demonstrates how biased datasets affect model performance.
Over-Optimization for Coherence: Models prioritize fluency over accuracy, generating
plausible yet incorrect outputs.
Lack of Grounding in Real-World Knowledge: Without mechanisms to verify facts,
models often produce misleading content.
Solutions:
Improving Training Data: Use diverse, up-to-date, and unbiased datasets to enhance
model reliability.
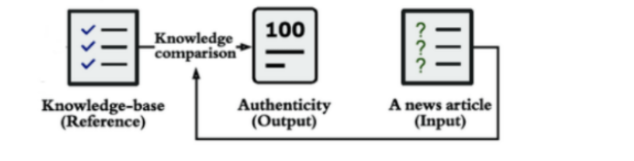
Fact-Checking Mechanisms: Integrate real-time verification tools like Wikipedia or
Wolfram Alpha.
The figure below illustrates a mechanism for verifying information in real time.
Uncertainty Estimation: Allow models to express uncertainty, enhancing transparency
and trust.
Future Directions:
Explore retrieval-augmented generation, combining LLMs with verified databases.
Develop standardized benchmarks to assess and compare hallucination rates.
Promote ethical AI practices to prioritize accuracy in critical applications.